Order of execution is one of the most critical and seemingly difficult aspects of using SuperCollider, but in reality it only takes a little thought in the early planning stages to make it work for you.
Introduction
Order of execution in this context doesn't mean the order in which statements are executed in the language (the client). It refers to the ordering of synth nodes on the server, which corresponds to the order in which their output is calculated each control cycle (blockSize). Whether or not you specify the order of execution, each synth and each group goes into a specific place in the chain of execution.
If you have on the server:
... all the unit generators associated with synth 1 will execute before those in synth 2 during each control cycle.
If you don't have any synths that use In.ar, you don't have to worry about order of execution. It only matters when one synth is reading the output of another.
The rule is simple: if you have a synth on the server (i.e. an "effect") that depends on the output from another synth (the "source"), the effect must appear later in the chain of nodes on the server than the source.
If you have:
The effect synth will not hear the source synth, and you won't get the results you want.
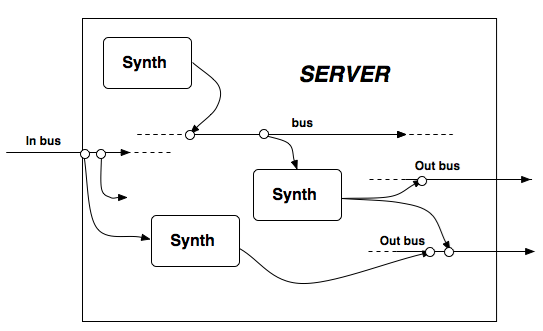
A diagram of a typical server configuration
On the server external signals can be received by synths from "public" input busses (one in the represented case), while the different synths must be connected to "public" out audio busses (two in the case) in order to output a signal externally to the soundcard (see Bus). Other busses (both control and audio) are internal. In general, busses can be thought as roughly analogous to sends, busses, or submixes on an analog mixer, or as pipes allowing one to route "flowing" signals. If a synth is connected to a bus at a certain point (thus "flowing" into it) a synth taking the signal from the same bus at a subsequent point will take as input the flowing signal (along with anything else previously output to the bus), just as would occur with a water pipe.
Some Notes about Servers and Targets
There is always a default Server, which can be accessed or set through the class method Server.default. At startup this is set to be the local Server, and is also assigned to the interpreter variable s.
When a Server is booted there is a top level group with an ID of 0 that defines the root of the node tree. This is represented by a subclass of Group: RootNode. There is also a Default Group with an ID of 1. This group is the default group for all Nodes. This is what you will get if you supply a Server as a target. If you don't specify a target or pass in nil, you will get the default group of the default Server.
The default group serves an important purpose: It provides a predictable basic Node tree so that methods such as Server:scope and Server:record can function without running into order of execution problems. Thus in general one should create new Nodes within the default group rather than in the RootNode. See Default Group and RootNode for more detail.
Controlling order of execution
There are three ways to control the order of execution: using addAction in your synth creation messages, moving nodes, and placing your synths in groups. Using groups is optional, but they are the most effective in helping you organize the order of execution.
Add actions
By specifying an addAction argument for Synth.new (or SynthDef.play, Function.play, etc.) one can specify the node's placement relative to a target. The target might be a group node, another synth node, or a server.
As noted above, the default target is the default_group (the group with nodeID 1) of the default Server.
The following Symbols are valid addActions for Synth.new: \addToHead, \addToTail, \addBefore, \addAfter, \addReplace.
Synth.new(defName, args, target, addAction)- if target is a Synth the \addToHead, and \addToTail methods will apply to that Synths group
- if target is a Server it will resolve to that Server's default group
- if target is nil it will resolve to the default group of the default Server
For each addAction there is also a corresponding convenience method of class Synth:
Synth.head(aGroup, defName, args)- add the new synth to the head of the group specified by aGroup
- if aGroup is a synth node, the new synth will be added to the head of that node's group
- if target is a Server it will resolve to that Server's default group
- if target is nil it will resolve to the default group of the default Server
Synth.tail(aGroup, defName, args)- add the new synth to the tail of the group specified by aGroup
- if aGroup is a synth node, the new synth will be added to the tail of that node's group
- if target is a Server it will resolve to that Server's default group
- if target is nil it will resolve to the default group of the default Server
Synth.before(aNode, defName, args)- add the new node just before the node specified by aNode.
Synth.after(aNode, defName, args)- add the new node just after the node specified by aNode.
Synth.replace(synthToReplace, defName, args)- the new node replaces the node specified by synthToReplace. The target node is freed.
Using Synth.new without an addAction will result in the default addAction. (You can check the default values for the arguments of any method by looking at a class' source code. See Internal-Snooping for more details.) Where order of execution matters, it is important that you specify an addAction, or use one of the convenience methods shown above.
Moving nodes
If you need to change the order of execution after synths and groups have been created, you can do this using move messages.
Groups
Groups can be moved in the same way as synths. When you move a group, all the synths in that group move with it. This is why groups are such an important tool for managing order of execution. (See the Group helpfile for details on this and other convenient aspects of Groups.)
In the above configuration, all of the synths in group 1 will execute before all of the synths in group 2. This is an easy, easy way to make the order of execution happen the way you want it to.
Determine your architecture, then make groups to support the architecture.
Parallel Groups
In some cases, server nodes do not depend on each other. On multiprocessor systems, these nodes could be evaluated on different CPUs. This can be achieved by adding those nodes to a parallel group (see ParGroup). Parallel Groups can be considered as Groups, whose contained nodes are not guaranteed to have a specific order of execution.
Using order of execution to your advantage
Before you start coding, plan out what you want and decide where the synths need to go.
A common configuration is to have a routine playing nodes, all of which need to be processed by a single effect. Plus, you want this effect to be separate from other things running at the same time. To be sure, you should place the synth -> effect chain on a private audio bus, then transfer it to the main output.
This is a perfect place to use a group:
To make the structure clearer in the code, one can also make a group for the effect (even if there's only one synth in it):
I'm going to throw a further wrench into the example by modulating a parameter (note length) using a control rate synth.
So, at the beginning of your program:
Note that in the routine, using a Group for the source synths allows their order to easily be specified relative to each other (they are added with the .tail method), without worrying about their order relative to the effect synth.
Note that this arrangement prevents errors in order of execution, through the use of a small amount of organizational code. Although straightforward here, this arrangement could easily be scaled to a larger project.
Messaging Style
The above examples are in 'object style'. Should you prefer to work in 'messaging style' there are corresponding messages to all of the methods shown above. See NodeMessaging, and Server-Command-Reference for more details.
Feedback
When the various output ugens (Out, OffsetOut, XOut) write data to a bus, they mix it with any data from the current cycle, but overwrite any data from the previous cycle. (ReplaceOut overwrites all data regardless.) Thus depending on node order, the data on a given bus may be from the current cycle or be one cycle old. In the case of input ugens (see In and InFeedback) In.ar checks the timestamp of any data it reads in and zeros any data from the previous cycle (for use within that synth; the data remains on the bus). This is fine for audio data, as it avoids feedback, but for control data it is useful to be able to read data from any place in the node order. For this reason In.kr also reads data that is older than the current cycle.
In some cases we might also want to read audio from a node later in the current node order. This is the purpose of InFeedback. The delay introduced by this is at maximum one block size, which equals about 0.0014 sec at the default block size and sample rate.
The variably mixing and overwriting behaviour of the output ugens can make order of execution crucial when using In.kr or InFeedback.ar. (No pun intended.) For example with a node order like the following the InFeedback ugen in Synth 2 will only receive data from Synth 1 (-> = write out; <- = read in):
- Synth 1 -> busA (this synth overwrites the output of Synth3 before it reaches Synth 2)
- Synth 2 (with InFeedback) <- busA
- Synth 3 -> busA
If Synth 1 were moved after Synth 2 then Synth 2's InFeedback would receive a mix of the output from Synth 1 and Synth 3. This would also be true if Synth 2 came after Synth1 and Synth 3. In both cases data from Synth 1 and Synth 3 would have the same time stamp (either current or from the previous cycle), so nothing would be overwritten.
(As well, if any In.ar wrote to busA earlier in the node order than Synth 2, it would zero the bus before Synth 3's data reached Synth 2. This is true even it there were no node before Synth 2 writing to busA.)
Because of this it is often useful to allocate a separate bus for feedback. With the following arrangement Synth 2 will receive data from Synth3 regardless of Synth 1's position in the node order.
- Synth 1 -> busA
- Synth 2 (with InFeedback) <- busB
- Synth 3 -> busB + busA
The following example demonstrates this issue with In.kr:
link::Guides/Order-of-execution::